En ce début février 2025, j’ai eu la chance de participer à la conférence-atelier de la section « Histoire de la communication » de l’ECREA qui portait sur l’histoire des réseaux de communication avant et après le web, et se tenait en Suisse, au CERN. Je pense que le choix du lieu n’a pas été étranger au succès de cet événement qui, aux dires des organisateurs et organisatrices, a suscité environ deux fois plus de propositions que leurs conférences habituelles, les conduisant à organiser l’ensemble de la conférence sur deux sessions parallèles. Mais bon, il faut dire qu’aller parler de l’histoire du web là où il a été créé, c’est quand même énorme !
J’avais pour ma part choisi cette conférence pour ma toute première communication autour de mon projet SkyTaste qui porte sur l’histoire de la plateforme Skyblog (pour en savoir plus sur ce projet et sur Skybox, son jumeau, ça se passe sur Webcorpora). Plusieurs raisons pour ce choix : d’abord pour l’ancrage disciplinaire, en effet il me tenait à cœur de le présenter dans une conférence d’historiens et historiennes. Mais aussi parce que l’appel à communication faisait la part belle à la question des imaginaires autour des réseaux, et je trouvais que ça collait bien. Je n’ai pas été déçue.
Je vous propose de revivre ici quelques temps forts de la conférence, sans aucune ambition de représentativité complète.
Matérialité des réseaux et écologie : imaginaire de la ruine
Quand on étudie principalement des réseaux numériques, soi-disant virtuels, la confrontation avec leur matérialité (enchevêtrements de câbles, salles machines, etc.) provoque toujours une certaine émotion. Il y a une poésie dans ces installations fonctionnelles dans lesquelles on n’a pourtant pas nécessairement injecté beaucoup d’amour et d’esthétique : d’ailleurs, le campus du CERN se pose là en la matière, tout y est gris et rectangulaire, ostensiblement moche, comme si réfléchir au design de ces bâtiments dédiés à la science dans ce qu’elle a de plus « dur » aurait risqué de les rendre moins sérieux. Mais bon, prenez un groupe de chercheurs et chercheuses en sciences humaines et déposez-les là, vous les entendrez s’extasier sur l’esthétique des poteaux téléphoniques, avouer (à l’image de Nicole Starosielski) que visiter le plus de « Cable Landing Stations » possibles dans le monde est leur but ultime dans la vie, ou encore prendre en photo frénétiquement les installations de communication vintage qui semblent ici encore en service.

Avec son film Do sheeps dream of electric ruins, Matt Parker, artiste multimédia, nous a proposé un moment hors du temps, sur les rives irlandaises, au milieu d’un troupeau de moutons qui reconquiert les ruines d’une ancienne station du télégraphe. Ça dure onze minutes, c’est contemplatif et poétique, ça parle de réseaux, de nature, de notre monde et de ce qu’il devient. Regardez-le.
Avant le web (et à côté)
Avez-vous déjà entendu parler des BBS (Bulletin Board Systems) ? Aviez-vous déjà pensé au rôle qu’a pu jouer le fax dans l’idée de travail à distance ? Comment faisait-on dans les années 1980 pour faire fonctionner un ordinateur personnel ? Saviez-vous qu’avec le fournisseur d’accès Freesbee, en 2000, aller sur Internet était « non seulement gratuit, mais moins cher » ? En abordant « l’avant » web, la conférence a permis de replacer l’histoire du web dans le temps long.
Jesper Verhoef nous a ainsi présenté le fax « en tant que proto-Internet » et montré comment celui-ci avait commencé à remettre en cause l’équilibre entre vie privée et professionnelle (bien avant que cette question ne se pose de nouveau autour de WeChat en Chine avec Yinan Sun). Kevin Driscoll a étudié le magazine Byte, qu’il assimile à une « communauté par voie postale » utilisant le courrier des lecteurs (et le courrier tout court) pour échanger des infos à une époque où quand on achetait un ordinateur, il ne contenait pas de programmes et il fallait les rentrer soi-même. Valérie Schafer s’est intéressée à la collection de kits d’accès à Internet d’Alain Letenneur pour découvrir ce que le CDrom peut avoir à nous apprendre sur l’Internet des années 2000, son modèle économique, son imaginaire. Niels Brügger a étudié la presse danoise entre 1979 et 1999 pour découvrir comment les réseaux informatiques étaient perçus au Danemark à l’époque (à voir absolument : le site vintage du projet Webhistorie.dk). Susan Aasman a retracé l’évolution de la vidéo en tant que média, des années 1970 à TikTok.
Je pourrais continuer à multiplier les exemples, citer toutes les communications que j’ai entendues (et aussi celles que j’ai loupées parce qu’il y avait deux sessions parallèles)… mais je crois que l’idée à retenir est surtout celle de la recherche d’une forme de continuité ou d’éclairage des transformations que nous vivons à l’heure de la culture numérique et d’Internet, à la lumière d’évolutions plus lointaines et profondes des moyens de communication.
Le berceau du web
Jouant le jeu de nous emmener à l’endroit précis où Tim Berners Lee a imaginé le web, dans le bâtiment 31, en face du data center, les organisateurices de la conférence ont aussi invité trois éminents témoins à nous raconter le CERN au tournant des années 1990 : Robert Cailliau, François Flückiger et Pier Giorgio Innocenti. C’était l’occasion de les entendre évoquer les différents facteurs qui ont fait du web, tel que pensé par Tim Berners Lee dans sa proposition initiale (la fameuse qui a récolté le commentaire « vague but exciting »), une réussite alors que tout le monde travaillait sur des idées similaires à l’époque. Parmi les ingrédients secrets évoqués :
- 50% de chance, si on en croit Robert Cailliau,
- le cerveau de Tim Berners Lee, que personne ne comprenait vraiment ^^ mais qui a pensé les choses de manière globale dès le début,
- une idée géniale : l’URL, une chaîne de caractères unique contenant à la fois un protocole, l’adresse d’un serveur, l’emplacement et le nom d’une ressource,
- le CERN lui-même, un lieu unique avec une forte expertise, pas de problèmes d’argent et une foule d’ingénieurs habitués à résoudre des problèmes,
- la simplicité : le web fonctionnait avec seulement deux standards, HTTP et HTML, presque trop simples pour attirer l’attention (au point que l’article proposé par Tim Berners Lee et Robert Cailliau à la conférence Hypertext de 1991 au Texas fut refusé),
- l’erreur 404 : le web pouvait fonctionner sans qu’on ait besoin de réparer tous les problèmes,
- enfin et peut-être surtout : la décision prise par le CERN de renoncer à ses droits sur l’invention, et l’utilisation d’une licence ouverte.




En 1995, François Flückiger publie le livre Understanding Networked Multimedia. Selon lui, la plupart des choses, bonnes ou mauvaises, qu’il y avait prédites se sont produites… Mais personne n’avait vu arriver les réseaux sociaux. Une question structurante en matière d’histoire du web.
Des émotions, toujours des émotions !
Les émotions étaient au rendez-vous à travers cette histoire des réseaux et du réseau, et au premier rang de celles-ci, la nostalgie. Le « web d’avant » apparaît comme un espace majoritairement, sinon totalement, tourné vers le partage de la connaissance, porté par des acteurs académiques ou associatifs, voire par les communautés elles-mêmes, espace d’expression d’une contre-culture s’opposant aux modèles de domination capitalistes (et autres).
Dans les travaux de l’initiative « Matter of imagination« , portée par Anya Shchetvina et Nathalie Fridzema, les émotions (nostalgie, beauté, intimité, esprit de jeu, confort…) et les imaginaires (avec des métaphores spatiales : jardins, maisons, autoroutes…) jouent un rôle important pour faire apparaître une opposition entre ce « web d’avant », plus personnel et authentique, et le web commercial contrôlé par les plateformes. Mais ce n’est pas seulement une question de nostalgie : c’est aussi une opposition économique entre le web vu comme un bien commun et les plateformes qui le transforment en espace privé. Se tourner vers le web du passé apparaît comme un moyen de contrecarrer les caractéristiques communes du web, en recherchant une expérience où le web est « lent » plutôt que rapide, « petit » plutôt que gigantesque. À l’exemple du Yesterweb, un mouvement né en 2021 sur Discord, on s’autorise à rêver d’un retour aux sources du web, en faisant la démarche de s’éloigner d’un « web principal » (core web) dominé par des plateformes commerciales en situation de monopole (typiquement, les GAFAM), pour aller vers un « web périphérique », plus discret et reposant sur d’autres modèles de gouvernance.
Nous avons été plusieurs à faire le lien entre ces émotions et la notion de patrimoine. Ainsi, Christian Schwarzenegger étudie la patrimonialisation du jeu vidéo en s’interrogeant sur les émotions liées à la jouabilité et aux réseaux de gamers, dans l’Allemagne des années 80. On retrouve le côté contre-culture, en découvrant comment les jeux vidéos parvenaient à passer le mur qui séparait l’Allemagne de l’Est et de l’Ouest et à permettre l’émergence de réseaux « pirates ». Mais ce n’est pas tout… En organisant des ateliers avec des communautés de gamers, Christian pose la question de ce qu’il est possible ou souhaitable de patrimonialiser pour rendre compte de cette expérience, cherchant tout particulièrement à identifier les émotions qui sont liées au jeu et les éléments qui sont susceptibles de les susciter à nouveau, dans la perspective de la collecte ou la création d’un nouvel objet patrimonial. La démarche est en fait très proche de ce que j’essaye de faire avec mon étude des émotions patrimoniales liées aux skyblogs (pour en savoir plus, vous pouvez consulter le résumé de mon intervention en attendant que je trouve un moyen / le temps de la publier).
Pour finir, un peu de théorie
Dans la dernière session parallèle à laquelle j’ai assisté, Leah Lievrouw et Paolo Bory sont revenus aux fondements théorique de l’analyse des réseaux en sociologie et en théorie de la communication : Gabriel Tarde (1843-1904) dont les théories ont bien plus tard influencé la théorie de l’acteur-réseau de Bruno Latour &co, Georg Simmel (1858-1918), Ferdinand Tönnies (1855-1936) et plus proches de nous, Paul Baran (auteur d’une représentation bien connue des différents types de réseaux), Patrice Flichy ou encore Pierre Musso.
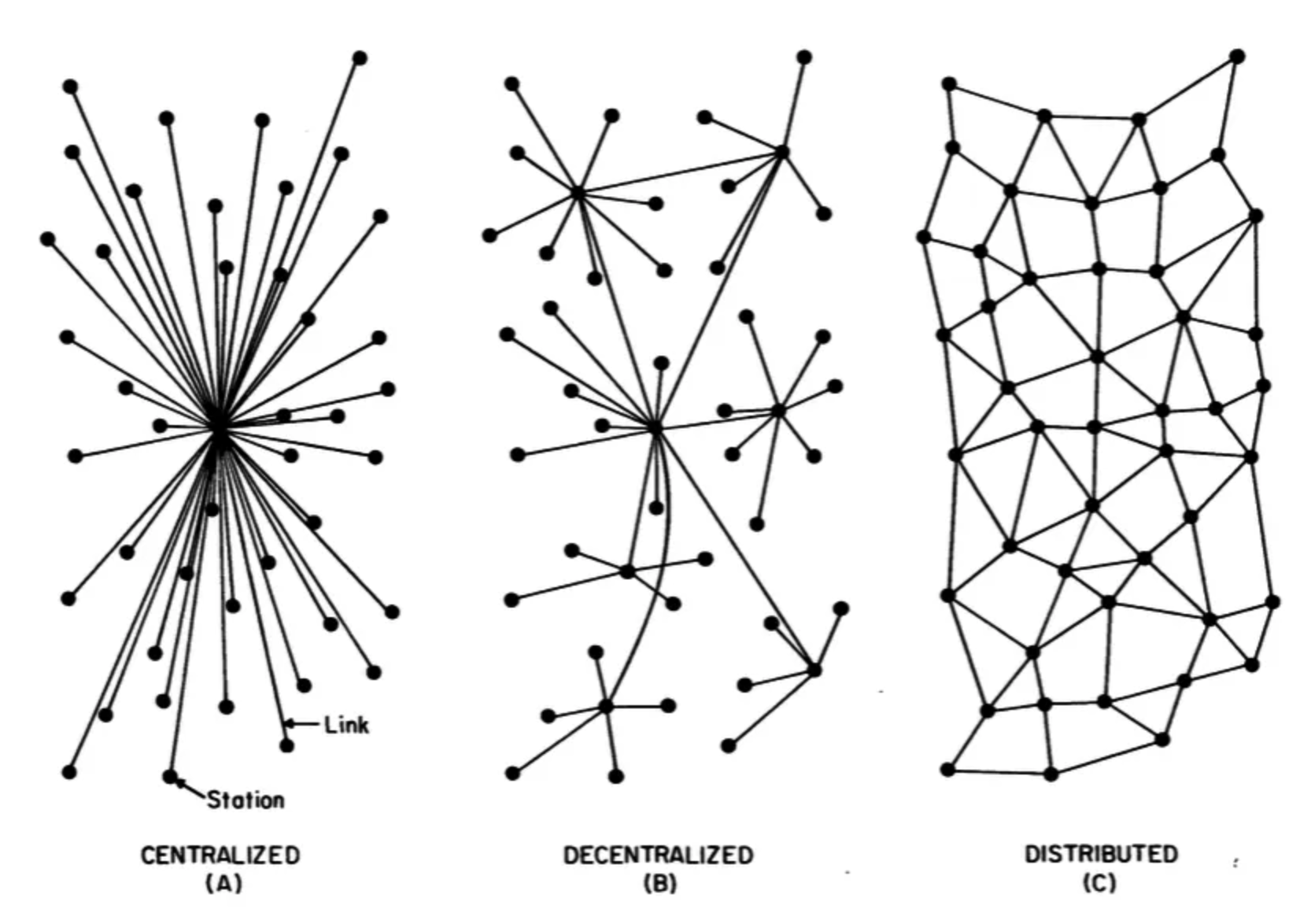
Ce retour aux fondamentaux fait apparaître une vision anti-structuraliste, « anti-Durkheim » des réseaux comme environnements inter-personnels qui commencent avec des relations sociales avant que leurs interactions ne fassent apparaître et évoluer des structures. À trop se focaliser sur la catégorisation des nœuds, plutôt que de s’intéresser à la nature constamment changeante (« ever-changing« ) des liens, les réseaux acquièrent une dimension aliénante. L’idée d’un réseau décentralisé comme le web portait de grands espoirs en terme de connexion, d’interopérabilité, de créativité, etc. De fait, à travers les plateformes, elle débouche sur un réseau atomisé, où les individus ne sont pas reliés mais divisés et séparés, tandis que le réseau ne cherche qu’à se nourrir lui-même. Est-ce vraiment le type de réseau que nous voulons ?
Quelques références
Fluckiger François, Understanding networked multimedia: applications and technology, London, Prentice Hall, 1995.
Berners-Lee Tim et Fischetti Mark, Weaving the Web: the past, present and future of the World Wide Web by its inventor, London, Orion business book, 1999.
Castells Manuel, The rise of network society, Oxford, Blackwell, 1999.
Brügger Niels (ed.), Web 25: histories from the first 25 years of the World Wide Web, New York, Peter Lang, 2017.
Aasman Susan, Fickers Andreas et Wachelder Joseph (eds.), Materializing memories: dispositifs, generations, amateurs, New York, Bloomsbury Academic, 2018.
Schafer Valérie (ed.), Temps et temporalités du Web, Nanterre, Presses universitaires de Paris Nanterre, 2018.
Brügger Niels, The archived web: doing history in the digital age, Cambridge, Massachusetts, MIT Press, 2018.
Turner Fred, Vannini Laurent et Cardon Dominique Préfacier, Aux sources de l’utopie numérique: de la contre-culture à la cyberculture, Stewart Brand, un homme d’influence, Caen, C&F éditions, 2021.
Musso Pierre, L’imaginaire du réseau, Paris, Editions Manucius, 2022.