
Alors que je préparais mon dernier (ou presque) cours de modélisation de l’année pour les TNAH, m’est venue l’idée saugrenue de faire un arbre de décision qui récapitulerait les critères de choix entre différents types de bases de données : relationnelles, NoSQL, graphes, colonnes, bases de données documents XML ou non, moteurs de recherche… Il y a beaucoup d’options et ce n’est pas toujours évident d’avoir les idées claires.
Je me suis donc tournée vers Gautier, dont le puits de slides reste la ressource n°1 en matière de formation à la donnée, pour qu’il m’aide à trouver les bonnes formulations et à raconter des choses pertinentes du point de vue de l’infrastructure technique. Il faut dire que cette question nous agite depuis pas mal de temps (on se souviendra des quelques nuits blanches qu’on a passées au moment où on a décidé de mettre les métadonnées de SPAR dans un triple-store RDF) et qu’on se sent un peu responsables du prosélytisme qu’on a pu faire autour des technologies du web sémantique, aujourd’hui largement remises en perspective (lire la série de 4 billets à ce sujet sur Les petites cases).
Néanmoins, après quelques années où j’ai carrément refusé de continuer à enseigner RDF et SPARQL en arguant que ça ne servait plus à rien (merci le creux de la désillusion), je constate actuellement un regain d’intérêt pour le web de données, notamment dans le contexte des données « FAIR » pour la recherche. Je vois régulièrement passer des fiches de stage / de poste qui demandent des compétences en web sémantique, que ce soit pour modéliser des ontologies ou pour faire des requêtes SPARQL. Il est donc important de continuer à former des ingénieurs et analystes des données dans ce domaine, mais en prenant la précaution de replacer cette technologie dans le paysage global des systèmes de gestion de données existant à l’heure actuelle. L’enjeu est de bien comprendre dans quels cas elle peut rendre des services, et dans quelles situations il vaut mieux se tourner vers autre chose.
Différents types de modèles
C’était donc le point de départ de ma démarche, et il m’a emmenée assez loin :
- d’abord, il a fallu rappeler que quand on parle de modélisation de données, on a en fait 3 couches de modèles :
- le modèle conceptuel, qui décrit des entités du monde réel et leurs relations,
- le modèle logique qui exprime les données sous une forme pouvant être manipulée par un traitement informatique,
- et le modèle physique qui correspond à la façon dont l’information est exprimée dans un format ou stockée dans un logiciel.

- À partir de là, j’ai pu détailler les principes et les spécificités des 3 types de modèles logiques :
- le modèle en tables, qui organise les données en tableaux où chaque colonne correspond à un attribut et chaque ligne à une instance ou enregistrement (c’est le modèle des bases de données relationnelles, mais aussi des jeux de données tabulaires en Excel ou CSV),
- le modèle d’arbre, adapté pour représenter une information organisée hiérarchiquement sous la forme de documents (par exemple, en XML ou en JSON),
- le modèle de graphe, où les données sont reliées entre elles suivant la logique des prédicats (en RDF) ou d’autres types de logique de graphe comme les property graphs.
- On va alors pouvoir s’intéresser aux différents types de SGBD (systèmes de gestion de base de données) qui correspondent à ces modèles :
- les bases de données relationnelles,
- les bases de données en colonnes,
- les bases de données document,
- les bases de données graphe.
Pour mémoire, ces « bases de données » ou plutôt ces « systèmes de gestion de bases de données » sont des logiciels qui assurent le stockage des données suivant un modèle logique, et fournissent des interfaces – souvent normalisées – pour interagir avec les données. Par exemple, dans une base de données relationnelle, les données sont stockées dans des tables et on interagit avec elles grâce au langage de requête SQL. Passons en revue de manière un peu plus détaillée ces différents outils.
Différents systèmes de gestion de base de données
Les bases de données relationnelles sont les doyennes de leur catégorie et en même temps, restent des outils fiables, solides et maîtrisés, qui peuvent rendre des services à différentes échelles, de la gestion d’informations personnelles en local jusqu’au pilotage d’énormes systèmes d’information. Elles sont efficaces pour stocker des données complexes dans des grandes volumétries, en offrant de bonnes performances en lecture (pour consulter les données) comme en écriture (pour produire et modifier les données).
Surtout, les bases relationnelles sont conformes aux propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité), c’est-à-dire qu’elles garantissent la gestion des transactions. Imaginons que vous ayez besoin de faire une modification dans vos données qui va impacter 500 enregistrements : c’est une transaction. Une fois que celle-ci est lancée, la base va soit l’exécuter jusqu’au bout, soit revenir à l’état initial (en cas de plantage par ex.) Si on lui demande une autre modification (une autre transaction) entre temps, celle-ci sera mise en file d’attente. Grâce à ce principe, la cohérence des données est garantie : il est impossible qu’une même donnée soit simultanément dans deux états différents.
Ces propriétés des bases de données relationnelles en font les favorites dans de nombreuses situations. Il peut toutefois arriver que vos données soient trop hétérogènes pour être exprimées en lignes et en colonnes : ainsi, lorsque je décris un inventaire d’archives, il m’est impossible de savoir à l’avance combien il aura de composants et comment j’aurai besoin de les décrire. Dans ce cas-là, d’autres modèles logiques peuvent être plus indiqués (on les regroupe parfois sous le nom de « NoSQL » ce qui veut juste dire que ce ne sont pas des bases de données relationnelles).
Une autre limite des bases de données relationnelles réside dans la contrainte de cohérence qu’imposent les principes ACID : il est (presque) impossible de les exécuter dans les environnements distribués qui caractérisent aujourd’hui le « big data ». En effet, ces environnements reposent sur le principe de scalabilité horizontale : quand j’ai besoin de plus de performance, je rajoute des machines en parallèle. Il devient alors difficile de continuer à garantir la cohérence des données, car elles peuvent être écrites et lues à différents endroits, avec un délai variable de synchronisation (je schématise sans doute beaucoup trop, mais vous voyez l’idée.)
Le théorème de CAP nous enseigne qu’un système ne peut pas être à la fois cohérent (C), toujours disponible (A pour Available) et distribué (P pour Partition) : les systèmes ACID se concentrent sur les deux premiers, et les systèmes distribués sur les deux derniers.
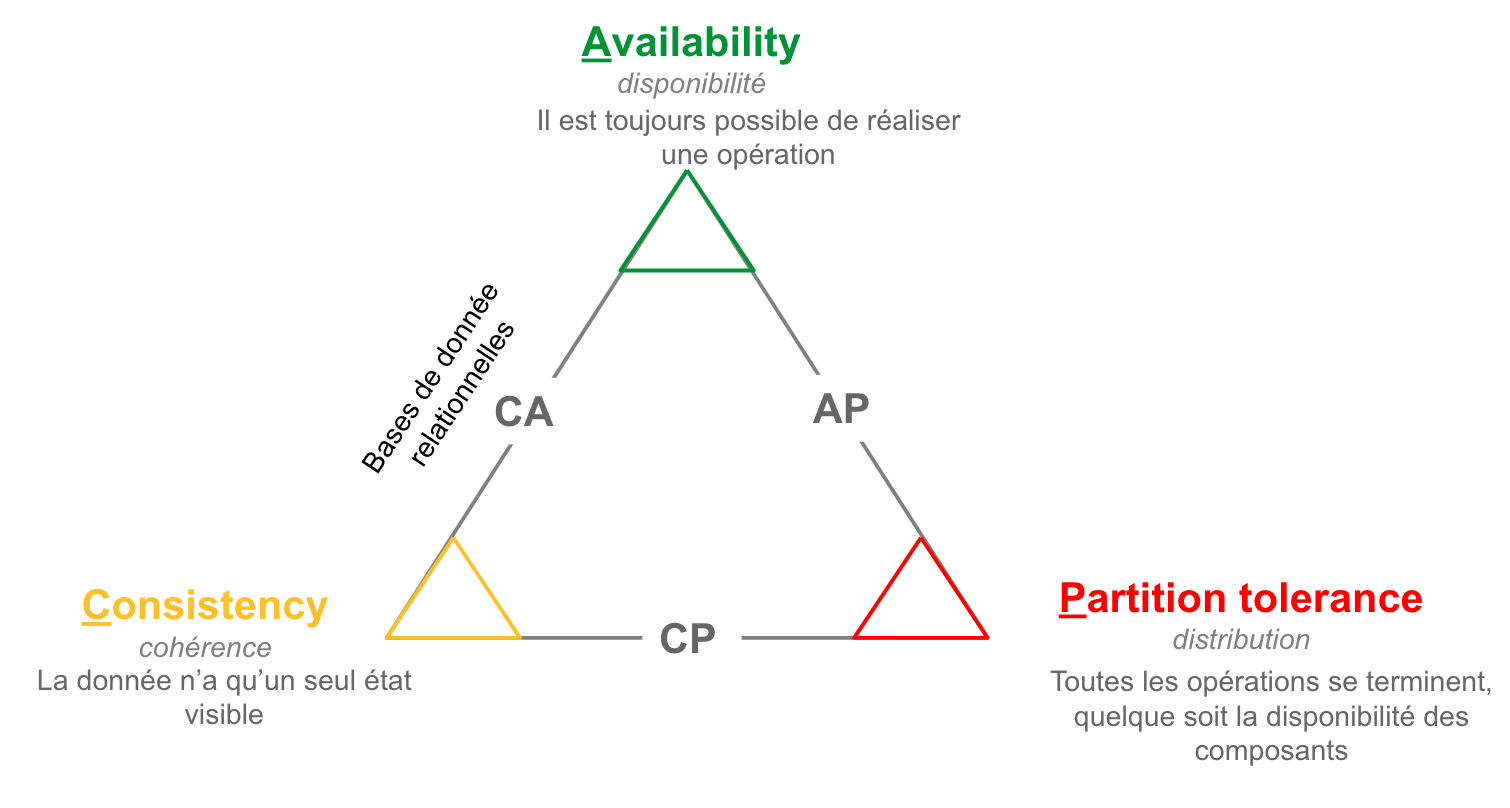
Si on a absolument besoin de scalabilité horizontale, et que le modèle est assez simple pour être réduit à une seule table, les bases de données en colonnes (Column Store) peuvent s’avérer utiles. Mais cela arrive quand même assez rarement dans le domaine des données culturelles et historiques, donc je ne m’étendrai pas sur ce scénario.
Les bases de données document sont conçues pour accueillir des données semi-structurées sous la forme de fichiers XML ou JSON par exemple. C’est pour cela qu’on parle de base de données orientée document : 1 fichier = 1 document. Elles permettent une montée en charge progressive des volumes de données, c’est à dire qu’il est relativement simple d’ajouter de nouvelles données (sous la forme de nouveaux documents ou fichiers) sans perturber les données existantes.
Leur principale contrainte est d’imposer un modèle centré sur une entité principale : pour que la base soit cohérente, il faut que tous les documents qui la composent soient de même nature (par exemple, des éditions de texte en TEI ou des inventaires d’archives en EAD). Cela va imposer une limite forte : si on a des données transverses à plusieurs documents (par ex. un référentiel de personnes pour les auteurs, producteurs, personnes évoquées ou représentées…) et que celles-ci sont modifiées fréquemment, il va falloir modifier tous les documents où ces données sont présentes, ce qui peut être assez lourd et surtout risqué. Sans la garantie ACID (voir ci-dessus, les bases relationnelles), on peut se retrouver dans une situation où une partie des documents est mise à jour, le système plante au milieu du processus, le reste n’est pas modifié… et paf, incohérence dans les données !
Le moteur de recherche est une base de données document dotée de fonctionnalités particulières : il facilite notamment la recherche plein texte (grâce à la constitution d’un index) et le filtrage par facettes des résultats. Il permet en outre de très bonnes performances en lecture (montée en charge du nombre d’utilisateurs et vitesse de réponse). Par contre, en raison des limites évoquées ci-dessus, on a plutôt tendance à l’utiliser comme stockage secondaire, c’est-à-dire qu’il va servir uniquement en lecture et pas en écriture, celle-ci étant assurée par un stockage primaire dans un autre type de base.

Finalement, si on a un modèle de données trop complexe pour l’exprimer sous forme de documents, et trop hétérogène pour qu’il rentre aisément dans une base de données relationnelle, cela vaut le coup de regarder du côté des bases de données graphes. Celles-ci sont aux données ce que la lampe magique est à Aladin : « des pouvoirs cosmiques phénoménaux… dans un vrai mouchoir de poche ! » (si vous m’avez lue jusque là, vous me pardonnerez la métaphore.)
Le mouchoir de poche, c’est le modèle de triplet (ou de quadruplet, ou autre, suivant le type de graphe que vous utilisez) : on réduit la complexité du modèle à une logique minimaliste et flexible, qui permet d’exprimer à peu près n’importe quoi (d’où les pouvoirs phénoménaux). Mais… all magic comes with a price. Et le prix à payer c’est que ces modèles sont relativement complexes à manipuler, avec des enjeux de maintenabilité et de performance.

Si le monde des graphes vous tente, la question est de savoir si vous avez besoin de placer votre graphe dans le web de données, pour faire le lien avec une communauté qui a décidé d’adopter les standards du web sémantique, notamment RDF et SPARQL (ce qui peut quand même être le cas assez souvent dans le domaine des données culturelles et des données de la recherche). Si oui, vous pouvez envisager d’utiliser un triple-store RDF. Mais il faut garder en tête que ces outils ont souvent des limites de performance et qu’ils sont assez peu maîtrisés dans l’industrie (ce qui veut dire qu’il sera difficile de trouver des prestataires pour les développer et les maintenir).
Si vous n’avez pas d’enjeu de diffusion web, pourquoi ne pas opter pour un autre type de graphe comme les « property graph » ? Cela permet de se débarrasser de certains détails agaçants comme la réification (acrobatie de modélisation nécessaire pour représenter certaines informations dans le modèle de triplet) ou les URI (parce que quand même, les URI, c’est compliqué, et si vous pensez le contraire je vous invite à venir expliquer le concept des préfixes en classe l’an prochain).
Malgré tout, ces outils ne vous offriront pas la même robustesse qu’une bonne vieille base de données relationnelle, et resteront plus difficiles à manier qu’une base orientée document (pour afficher le graphe, il faut le redocumentariser de toute façon, c’est-à-dire choisir les triplets qui décrivent une entité et les réunir dans un document JSON, XML ou autre). Cela vaut donc quand même le coup de se demander si l’exposition dans un SPARQL endpoint ne peut pas être un stockage secondaire : au passage, c’est le cas dans data.bnf.fr, qui est construit avec l’outil Cubicweb de Logilab dans lequel les données sont stockées sous la forme d’une base de données relationnelle, quand bien même on a un modèle logique en RDF (cf ci-dessus : dans ce cas précis, il y a une différence entre le modèle logique et le modèle physique). De la même manière, si on a des données stockées de façon primaire sous forme de graphe, disposer d’un stockage secondaire de type moteur de recherche peut aider à résoudre par exemple des problèmes de performance ou à simplifier l’accès aux données.
L’arbre de décision
Après toutes ces réflexions (pfiou !), nous voici prêts à parcourir l’arbre de décision qui résume tout cela :

Cet arbre de décision part du principe que vous avez déjà défini votre modèle conceptuel, que vous savez donc de combien de classes et de relations vous avez besoin, quels sont les attributs de vos entités et s’ils sont plutôt homogènes (toutes les instances d’une classe sont décrites de la même manière) ou pas.
La partie haute du schéma vous permet de déterminer quel est le meilleur modèle logique en fonction de votre modèle conceptuel.
La partie du milieu vous permet de déterminer quel est le meilleur type de système de gestion de base de données en fonction de vos usages.
Enfin, la partie du bas identifie les cas où l’on peut avoir besoin d’un stockage secondaire.
Il a fallu 134 diapos à Gautier pour expliquer tout cela. De mon côté, j’y passe une vingtaine d’heures en cours. Ici je vous propose une grosse tartine de texte assortie d’un outil de pensée visuelle : il va de soi que cela n’épuise pas le sujet, mais j’espère quand même que ce billet pourra rendre quelques services (que celles et ceux qui veulent qu’on écrive un manuel complet sur la data lèvent la main !)





{kind=link}