Aujourd’hui, je vous parle d’une application de l’intelligence artificielle et plus spécifiquement, des modèles de langues et de l’IA générative, qui est en train de prendre pas mal d’essor en ce moment : le RAG (Retrieval Augmented Generation). Vous n’en avez jamais entendu parler ? Restez branchés, car le RAG pourrait bien rentrer rapidement dans la boîte à outil courante du professionnel de l’information, juste à côté des catalogues, des ressources électroniques et des moteurs de recherche.

Un peu d’historique et de contexte (on ne se refait pas)
Voilà plusieurs années maintenant qu’on me demande régulièrement d’intervenir pour parler de ce que l’IA change ou va changer dans les bibliothèques. Après avoir étudié tous les use-case possibles et imaginables, j’ai développé un savant exercice d’équilibriste à base de « on va pouvoir continuer à faire ce qu’on fait, mais plus efficacement » ou encore « c’est surtout la masse de ce qu’on peut traiter qui change ». Depuis plusieurs années, j’avais vu débarquer les grands modèles de langue (LLM), en particulier BERT et ses petits amis (CamemBERT, FlauBERT etc.) mais globalement, leur utilisation se passait dans la soute, dans des profondeurs techniques difficiles à expliquer à des publics non-avertis. Cela faisait partie de ces outils « invisibles » qui améliorent les données et les services qu’elles rendent, mais sans faire de bruit.
En novembre 2022, quand ChatGPT a débarqué et a démontré sa capacité à masteriser le test de Turing, j’ai été assez rapidement convaincue qu’une fois le phénomène de mode passé, cet outil (et ses petits frères LLM) aurait surtout un impact quand il s’intègrerait discrètement dans nos applications du quotidien : nos gestionnaires de mail (pour répondre plus vite et envoyer encore plus de mails :-/), nos traitements de texte (pour trouver le bon mot à notre place) et… nos moteurs de recherche (dont il reformulerait à la fois les réponses et les questions, en langage naturel).
Le graal du « langage naturel » dans la recherche documentaire est en effet un idéal après lequel on court depuis bien des années. L’enjeu est de se débarrasser des mots-clefs, méthodes de requêtage et autres trucs de professionnels de l’information, pour pouvoir simplement demander les choses à son moteur de recherche préféré comme on le ferait à un humain, en lui posant des questions. La recherche plein texte à la Google ne répond qu’imparfaitement à ce cas d’usage : on peut en effet formuler des questions, il répondra bien quelque chose, mais le lien entre les deux n’est pas garanti.
Comme nous autres bibliothécaires, Google a commencé par tenter de s’appuyer sur les métadonnées pour pouvoir répondre de manière pertinente à au moins certaines questions, avec le « knowledge graph ». Ce qui donne par exemple ceci :
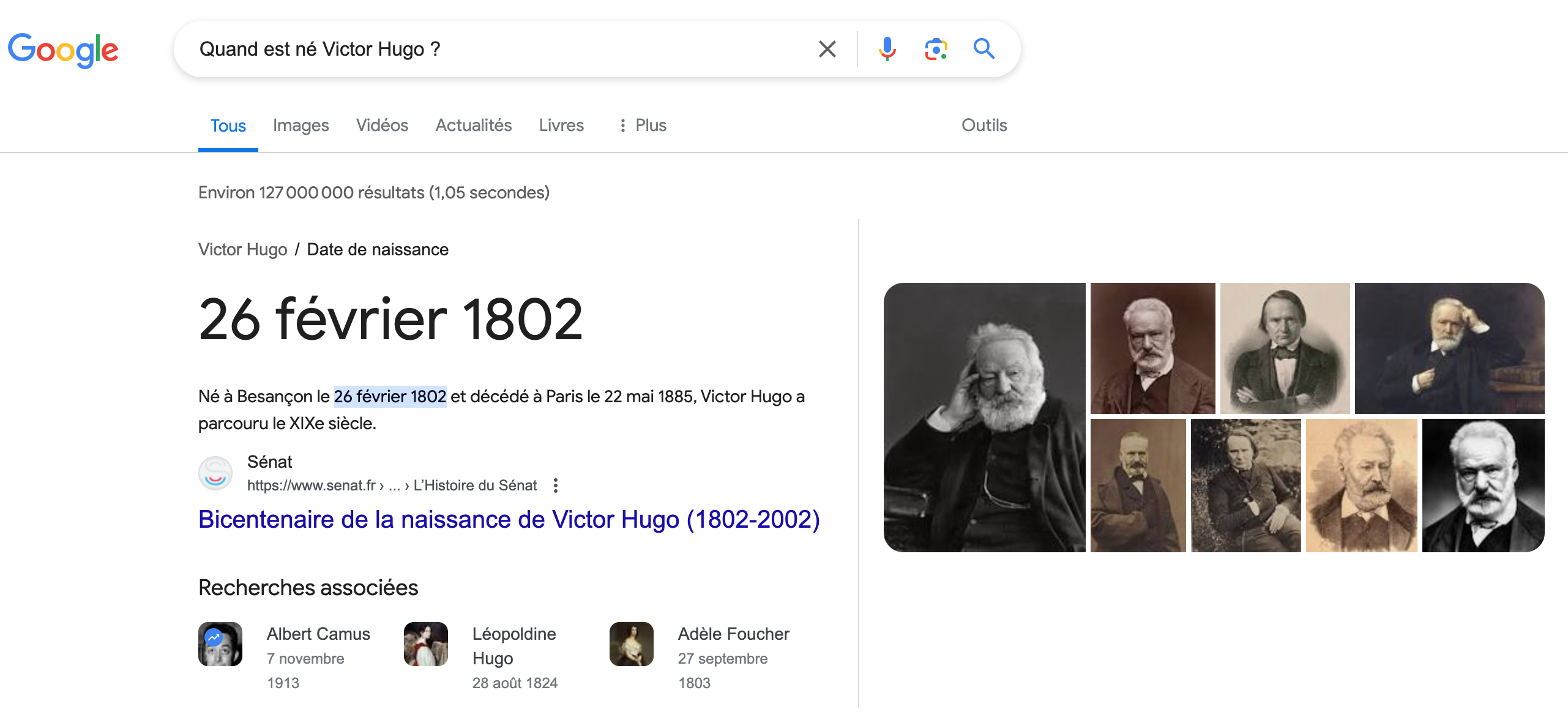
Encore plus récemment, on a vu apparaître autre chose dans la liste de résultats de Google. Dans la copie d’écran ci-dessous, prise à partir de la même question et toujours sur la 1e page de résultats, vous avez à droite le knowledge graph et à gauche, une liste de questions avec leurs réponses (que l’on peut dérouler en cliquant sur la flèche) :

Il suffit de regarder attentivement les questions et les réponses pour deviner que Google utilise ici les ingrédients de sa bonne vieille recette qui marche : analyser les questions que posent souvent les internautes, les réponses qui leur plaisent le plus, et chercher les chaînes de caractère textuelles qui correspondent. Rien de neuf : on sait depuis longtemps que pour améliorer son référencement, il faut formuler le titre de ses pages/billets/vidéos sous forme de question en essayant d’imaginer ce que les internautes se demandent (vraiment, j’avais capté ça en 2004, ce qui a fait de ce billet mon best-seller de tous les temps).
Ce qui change vraiment, c’est la place importante que Google réserve désormais à ce bloc question-réponse sur sa page de résultats, quelle que soit la requête (même si ce n’est pas une question). On peut donc s’aventurer à le prédire : dès qu’on aura réussi à empêcher les LLM de trop halluciner, les modalités de la recherche documentaire vont profondément changer, et laisseront beaucoup plus de place aux questions-réponses et aux échanges en langage naturel.
Je ne m’appesantirai pas ici sur les tests en cours dans ce domaine du côté des grands moteurs de recherche du web, qu’il s’agisse de Google ex-Bard désormais Gemini ou du Copilot de Bing basé sur ChatGPT. Ce qui m’intéresse aujourd’hui, c’est de vous parler de l’un des impacts de cette évolution sur la recherche documentaire en bibliothèque (ou archives), à travers le RAG.
Qu’est-ce que le RAG et à quoi peut-il servir ?
(Ce titre de niveau H2 est cadeau pour le référencement.)
RAG signifie donc Retrieval Augmented Generation ; en français, on parle de « génération augmentée de récupération ».
Un RAG permet à une intelligence artificielle générative conversationnelle (comme ChatGPT) d’interagir avec un corpus délimité. Celui-ci peut correspondre à un ensemble de documents, un fonds d’archives ou même à un seul document. On peut dès lors poser des questions visant à résumer tout ou partie du corpus ou du document, à vérifier la présence de tel ou tel concept et savoir comment il est traité, ou encore à répondre à des questions précises en se basant sur l’information présente dans le corpus. Bonus non négligeable, grâce au RAG, l’outil est en principe capable de citer ses sources c’est à dire de lister précisément les documents du corpus sur lesquels il s’est basé pour répondre, voire de fournir des extraits et des citations.
Imaginez par exemple que vous tombez sur un article de 50 pages potentiellement intéressant, mais vous n’avez pas le temps de le lire. Vous pourriez alors demander à un agent conversationnel, grâce à votre RAG, de vous le résumer paragraphe par paragraphe, d’en extraire les thématiques principales, de vérifier s’il contient l’idée que vous cherchez ou la réponse à votre question, d’aller droit aux résultats de la recherche qui y est présentée… C’est le cas d’usage qu’a imaginé JSTOR pour son outil AI research tool (beta) :

Les RAG semblent être apparus en 2020 dans l’environnement de Meta. Pour ma part, je les ai découverts (notamment à travers l’exemple de JSTOR) à la conférence AI4LAM de Vancouver en novembre dernier ; néanmoins je ne crois pas que le terme de RAG a été utilisé (ou alors il m’a échappé, on en sera quittes pour vérifier dans les captations vidéo qui devraient arriver bientôt). Sur le coup, j’ai trouvé l’idée intéressante mais un peu anecdotique, peut-être parce que la personne qui faisait l’une des démos avait utilisé ses propres archives et posait des questions sur son chien (les exemples, c’est important). Depuis, j’ai vu passer d’autres applications qui ont attiré mon attention et que je détaillerai un peu plus loin (ça c’est pour vous obliger à lire jusqu’au bout mon billet interminable, quel machiavélisme !)
Comment ça marche ?
Je ne vais pas rentrer dans des détails très techniques, ce qui m’intéresse est comme d’habitude de saisir suffisamment les principes généraux pour comprendre les atouts et les limites potentielles de l’outil.
Les grands modèles de langue comme Chat-GPT présentent la particularité de mélanger une fonction linguistique (construire des phrases correctes dans plusieurs langues) et des connaissances, qui s’appuient sur les données d’apprentissage qui leur sont fournies à savoir, globalement, de grands corpus de texte issus du web ou de bibliothèques numériques. Or, le mélange de ces deux fonctions produit le phénomène qu’on a appelé hallucination, c’est-à-dire que lorsque le modèle n’a pas la connaissance nécessaire, il produit quand même du langage et donc raconte n’importe quoi. Essayez par exemple de demander à Chat-GPT de vous générer la bibliographie d’une personne, il vous fournira des références crédibles mais totalement fantaisistes… Par exemple je n’ai rien écrit de tout cela (encore que l’idée d’une co-publication avec Nathalie Clot soit bien trouvée) :

On ne peut pas vraiment lui en vouloir : ChatGPT est un modèle de langue, son rôle est de générer du langage et pas de rechercher des informations.
Le principe du RAG est donc d’augmenter (A) la fonction générative (G) avec une fonction de recherche (R) dans un corpus externe. Pour effectuer cette spécialisation, il existe plusieurs méthodes possibles : entre l’article initial de P. Lewis et al. en 2020 et celui-ci qui, en 2023-24, analyse 100 publications à propos des RAG, le champ de la recherche s’est déjà complexifié de manière importante, notamment suite à l’irruption de ChatGPT en cours de route. Le schéma ci-dessous, emprunté au 2e article, représente la généalogie de l’évolution des RAG pendant cette période :

Je recommande également la lecture de cet article pour les personnes qui souhaiteraient des explications techniques claires et illustrées par des schémas sur le fonctionnement de ces différents types de RAG. Je vais essayer de résumer, mais comme le laisse supposer ce joli graphique, le RAG est un domaine de recherche complexe en plein expansion, qu’il serait difficile de saisir en seulement quelques phrases : je vais donc forcément simplifier de façon un peu caricacturale, pardonnez-moi.
Il y a en gros trois méthodes pour améliorer les résultats d’un LLM en maîtrisant davantage la source des connaissances qu’il utilise pour répondre :
- le prompt-engineering, qui consiste à agir au niveau du prompt, en y injectant le contenu des références à utiliser pour fournir une réponse correcte et à jour,
- le fine-tuning, qui consiste à réentraîner le modèle sur un corpus choisi pour lui apprendre à répondre de manière plus spécifique en fonction d’un domaine ou d’un corpus,
- le RAG proprement dit, qui repose sur la séparation de la fonction langagière du LLM et de la base de connaissances qui la sous-tend.
En réalité, selon les types de RAG, on va combiner ces différentes méthodes pour optimiser les résultats obtenus. Par exemple, en injectant des sources de référence dans les prompts, on va permettre au LLM de tracer l’origine des connaissances qu’il utilise pour formuler sa réponse, voire lui donner des éléments pour fournir des réponses plus à jour (la base de connaissance de la version publique de ChatGPT, par exemple, s’arrête en 2021). Par contre, il existe des risques de brouillage entre les connaissances d’origine du modèle et le corpus choisi. Le fine-tuning nécessite de réentraîner le modèle, ce qui peut être assez lourd en terme de calcul et nécessite de disposer de grands corpus de vérité terrain adaptés. En revanche, le fait de séparer le langage des connaissances a l’avantage de permettre de travailler avec des modèles de langue plus légers – c’est ce que nous a expliqué Pierre-Carl Langlais à la dernière réunion du chapitre francophone d’AI4LAM que vous avez manquée malheureusement, mais que vous devriez pouvoir revoir en vidéo bientôt.
Des exemples ?
Si vous voulez en savoir plus sur le principe des RAG, lire des explications un peu plus techniques (mais quand même accessibles) et découvrir un outil que vous pouvez vous-même tester, allez voir du côté de WARC-GPT, un outil open-source développé par le Lab de l’Université de Harvard (présentation – github). Son objectif est de permettre d’explorer des paquets d’archives web au format WARC. Vous allez me dire que si vous ne travaillez pas sur les archives du web, ce n’est pas très intéressant… et pourtant ! Si vous utilisez des ressources accessibles en ligne comme à peu près n’importe qui, il est globalement très facile de les empaqueter en WARC (par exemple avec Conifer ou Archiveweb.page).
Sinon, vous pouvez aussi tester Nicolay, un outil qui expérimente le RAG sur 15 discours d’Abraham Lincoln, représentant environ 300 pages de texte (présentation – démo – github).
Au niveau français, j’ai aperçu des expérimentations à droite ou à gauche, mais je n’ai rien de concluant à vous montrer pour l’instant. Pourtant, si on en croit les très nombreuses références commerciales que l’on peut trouver sur Internet, comme par exemple celle-ci (qui est par ailleurs plutôt bien faite pour qui recherche des explications en français), le RAG est aujourd’hui une technologie bien maîtrisée par l’industrie. Donc si vous avez des exemples sous la main, n’hésitez pas à me les signaler, je les ajouterai à ce billet.
Pour revenir au domaine de la recherche documentaire et des bibliothèques, il me semble que le RAG offre des opportunités d’exploration de grands corpus que je serais surprise de ne pas voir fleurir dans les mois ou années qui viennent. Par ailleurs, si ce genre de méthode doit révolutionner à terme la recherche documentaire et voir nos recherches par mots-clef disparaître au profit de prompts, comme la recherche par équation a disparu au profit de de la recherche plein texte… On a intérêt à comprendre comment elles fonctionnent et à apprendre à les maîtriser. Car le prompting, c’est comme la recherche documentaire : ça pourrait paraître simple à première vue, mais c’est une compétence de la litératie numérique qui ne s’invente pas.
Je vous propose de conclure ce billet en écoutant The entertainer’s Rag (Tony Parenti’s Ragpickers Trio, 1958) sur Gallica. RAG time !
Ce billet a été rédigé à 100% à base d’intelligence humaine.
Edit 15/01/2025 : On y est. Avant-hier, Google Scholar était un moteur de recherche. Aujourd’hui c’est un chatbot.